Original: Components of A Coding Agent https://magazine.sebastianraschka.com/p/components-of-a-coding-agent
Author: Sebastian Raschka, PhD
How Coding Agents in Practice Leverage Tools, Memory, and Repository Context to Unlock Greater Power from Large Language Models
In this article, I want to talk about the overall design of Coding Agents and Agent harnesses. What exactly are they? How do they work? How do the various components coordinate in practical applications? Since readers often ask me about agents (many have read my books “Build a Large Language Model (From Scratch)” and “Build a Reasoning Model (From Scratch)”), I decided to write this reference guide to share with everyone conveniently in the future.
Broadly speaking, the reason agents are so hot right now is due to recent advancements in practical large language models (LLMs). It’s not just about the models themselves getting stronger, but more about how we use them. In many real-world deployment scenarios, the surrounding systems—like tool calling, context management, and memory functions—play a role no less significant than the model itself. This explains why systems like Claude Code or Codex feel much more powerful than chatting directly with their underlying models in a standard chat interface.
Next, I will outline the six core modules of a coding agent.
Claude Code, Codex CLI, and Other Coding Agents
You might already be familiar with Claude Code or Codex CLI (CLI stands for Command Line Interface, a tool that allows users to operate a computer by typing code/commands in a terminal). To set a simple baseline: they are essentially agentified programming tools. They wrap a large language model within an application layer (what we call an Agent harness), making them more convenient and performant when handling programming tasks.
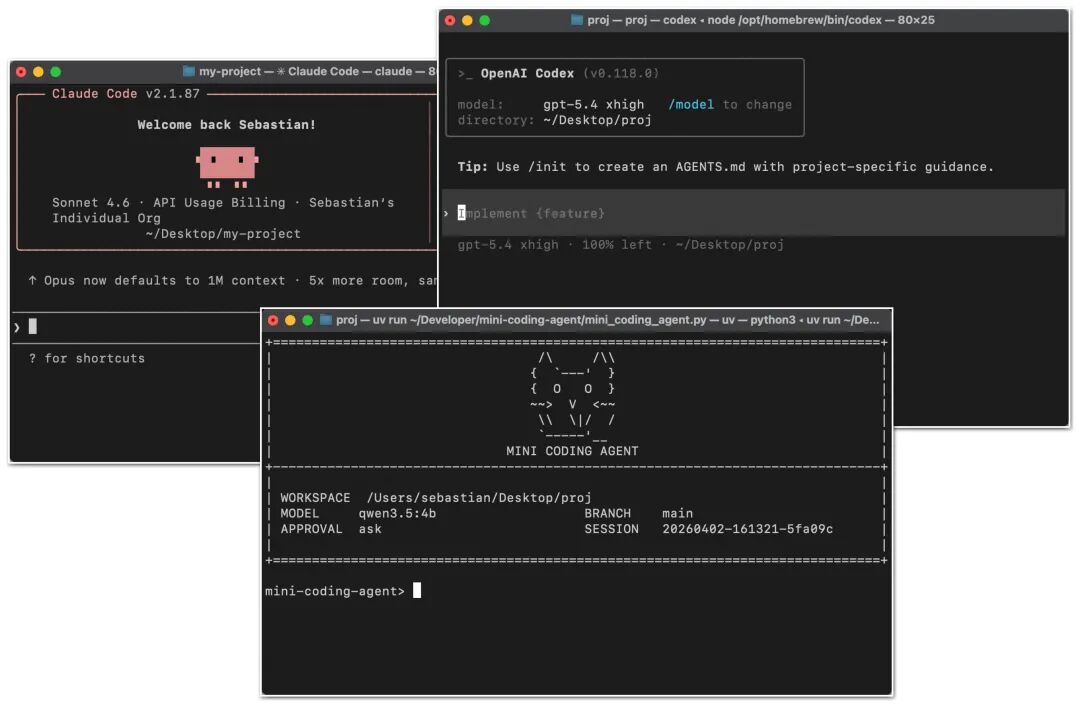 Figure 1: Claude Code CLI, Codex CLI, and my own minimalist coding agent.
Figure 1: Claude Code CLI, Codex CLI, and my own minimalist coding agent.
Coding agents are specifically built for software development. Here, the main event isn’t just which model you choose, but the surrounding support systems—including repository context (Repo Context), tool design, prompt cache stability, memory capabilities, and the coherence to handle long, continuous work sessions.
Understanding this distinction is crucial. Because when we talk about “the programming ability of large language models,” people often conflate “the model itself,” “the model’s reasoning behavior,” and “agent products.” So before diving into the details of coding agents, let me spend a moment briefly clarifying the differences between the broad concepts of large language models, reasoning models, and agents.
Clarifying Relationships: Large Language Models, Reasoning Models, and Agents
Large Language Model (LLM) is the core; essentially, it’s a model that continuously predicts the “next word.” Reasoning Model is also an LLM, but it has undergone special training or prompt guidance to invest more computational power in generating answers (i.e., increasing inference-time compute consumption, known as test-time compute) for intermediate step reasoning, self-verification, or searching for the best result among multiple candidate answers.
Agent is a layer on top of the model; you can think of it as a “control loop” operating around the model. Typically, it works like this: you give a goal, and the agent layer (or Harness) makes decisions for the model: what to check next? Which tool to call? How to update the current state? When is the task complete and it can stop?
To use an imperfect but intuitive analogy: an LLM is like a regular engine; a reasoning model is a souped-up, more powerful engine (and, of course, more expensive); and an Agent harness is the entire vehicle system that helps us better harness that engine. Although we can also use LLMs and reasoning models directly in a chat interface or Python code, I hope this metaphor clarifies their relationship.
 Figure 2: The relationship between a regular large language model, a reasoning large language model (or reasoning model), and a large language model wrapped in an Agent harness.
Figure 2: The relationship between a regular large language model, a reasoning large language model (or reasoning model), and a large language model wrapped in an Agent harness.
In other words, an agent is a system that continuously calls the model in a loop within a specific environment.
To summarize:
-
• Large Language Model (LLM): The most primitive foundational model. -
• Reasoning Model: An optimized LLM, specifically designed to output intermediate reasoning steps (what we often call Chain of Thought) and enhance self-verification capabilities. -
• Agent: A loop system containing “model + tools + memory + environmental feedback.” -
• Agent harness (Agent Runtime Framework): The software scaffolding built around the agent, responsible for managing context, tool calls, prompts, state, and control flow. -
• Coding harness (Coding Runtime Framework): A “specialized version” of the Agent harness, tailored specifically for software engineering, responsible for managing code context, development tools, code execution, and iterative feedback.
As listed above, when discussing agents and programming tools, we often encounter these two terms: Agent harness (Agent Runtime Framework) and Coding harness (Coding Runtime Framework). A Coding harness is the software scaffolding that helps models write and modify code efficiently. An Agent harness has a broader scope, not limited to programming (e.g., OpenClaw). Both Codex and Claude Code can be considered Coding harnesses.
In summary: a better LLM provides a more solid foundation for reasoning models (which still require